

详细介绍
MinerU是一款由上海人工智能实验室(上海 AI 实验室)OpenDataLab 团队开发的开源智能数据提取工具,专注于将复杂 PDF 文档高效解析与提取。它能够将包含图片、公式、表格、脚注等多模态元素的 PDF 文档精准转化为清晰、易于分析的格式,如 Markdown、JSON、Docx、HTML、LaTeX 等。
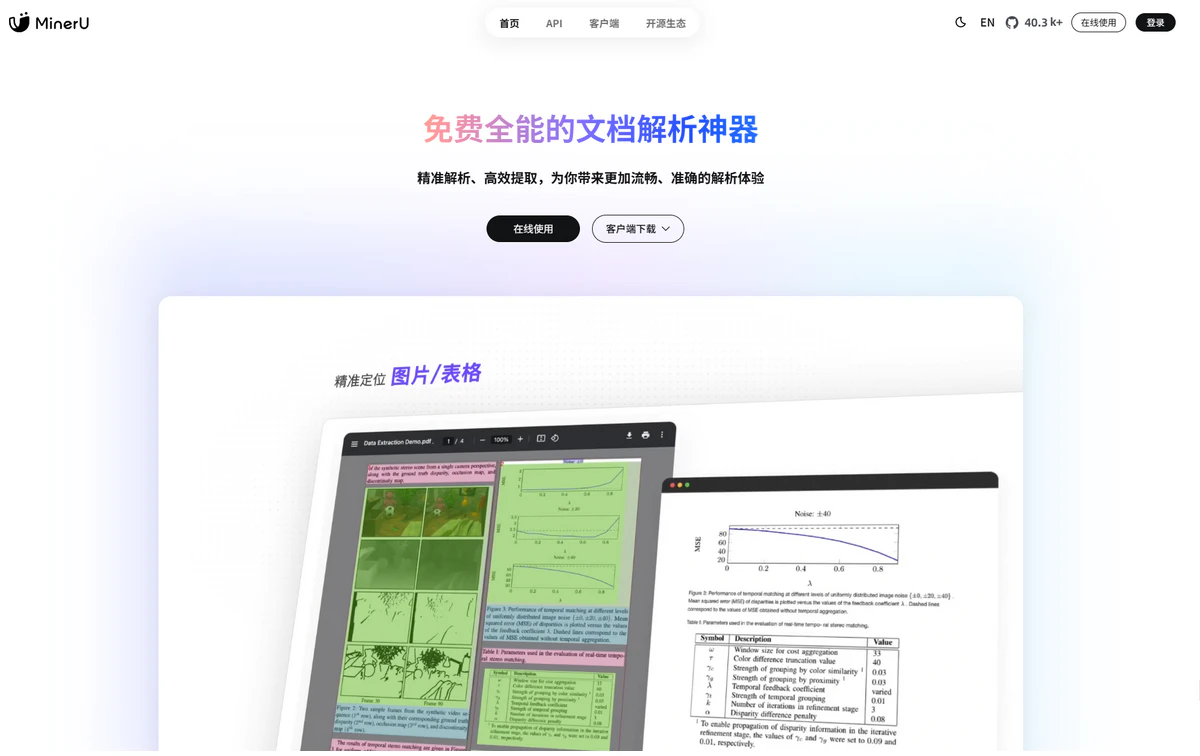
主要功能
- 多格式支持:支持 PDF、Word、PPT、图片等多种文档格式的解析。
- 精准提取:能够准确提取文档中的文字、公式、表格、图片等元素。
- 多语言识别:支持 84 种语言的 OCR 识别,包括繁简中文、英文、日文等。
- 批量处理:支持批量上传和解析文档,提升处理效率。
- 实时预览:支持原文与解析内容联动预览,方便校对和修改。
- 多格式导出:支持 Markdown、JSON、Docx、HTML、LaTeX 等多种格式的导出。
- 自动语言识别:自动识别文档语言并选择合适的 OCR 模型。
- 离线部署:支持完全离线部署,无需网络依赖,确保数据安全。
使用方法
- 安装客户端:从 MinerU 官网下载并安装桌面客户端。
- 配置环境:根据需求安装 Python 环境及相关依赖,具体步骤可参考 GitHub 安装指南。
- 下载模型文件:按照指南下载模型权重文件,确保模型正常运行。
- 启动客户端:打开客户端,将文档拖拽到界面或输入文件 URL,选择导出格式和配置参数。
- 开始解析:点击解析按钮,等待解析完成,导出所需格式的文件。
- 使用 API:开发者可通过 MinerU API 提交解析任务,获取解析结果。
官方资源
- 项目地址:MinerU GitHub 仓库
- PDF 模型解析工具链代码:PDF-Extract-Kit GitHub 仓库
- 客户端下载地址:MinerU 官方网站
应用场景
- 学术研究:科研人员可将学术论文 PDF 转换为 Markdown 格式,方便引用和进一步分析。
- 数据分析:数据分析师可利用 MinerU 提取财务报告中的关键数据,用于后续分析。
- 法律文件处理:法律从业者可快速提取法律文件中的重要条款和内容。
- 电子书籍转换:将电子书籍转换为可编辑的 Markdown 格式,便于进一步编辑和分享。
- AI 语料准备:助力各行业利用大模型、RAG 等技术,结合学术文献、财务报告、法律文件等专业文档,打造垂直领域的新知识引擎。



